��ԭ�� Understanding LTE with MATLAB ,����Houman Zarrinkoub�����������nj�(du��)��ԓ���ķ��g�����еČ��I(y��)���~�R�o����Ӣ��ԭ��������D�ͱ����Ű涼�Dž���ԭ�ģ����g����(zh��n)�_�ĵط�Ո(q��ng)�x�߶��������
���ăH���ڂ�(g��)�ˌW(xu��)��(x��)���о�����������������������̘I(y��)��;��������

4.3 �ŵ����a
��Ŀǰ��ֹ��������҂��ѽ�(j��ng)ӑՓ���������ŵ�̎���Ј�(zh��)�е��{(di��o)�ƺͼӔ_���������F(xi��n)���҂����Y(ji��)��TrCH̎��������ŵ����a��������c�{(di��o)�ƺͼӔ_����҂�����B����turbo���a�ļm�e(cu��)���a����CRC�z�y(c��)��������e(cu��)�`�z�y(c��)�C(j��)�ơ���4.3���Y(ji��)�˸��NTrCH���ŵ����a�����������˻��ھ��e���a�ďV���ŵ�(BCH)�����������(sh��)�����ŵ�������turbo���a���
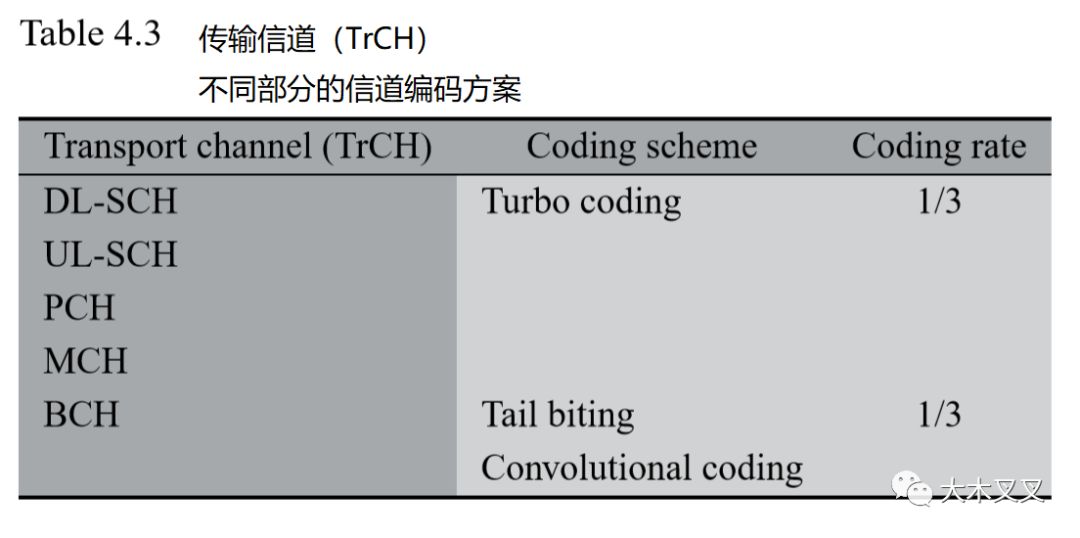
Turbo���a��LTE��(bi��o)��(zh��n)��Ҏ(gu��)�����ŵ����a�Ļ��A(ch��)���M��turbo���a���S����ǰ�Ę�(bi��o)��(zh��n)���ѽ�(j��ng)��ʹ��������������һֱ��ҕ���c�������e���a����һ��Ŀ��x�M����Ȼ�����������LTE�У�turbo���a���ŵ����a�C(j��)�Ƶ��(q��)��(d��ng)���������������҂��Ľ̌W(xu��)���������҂�������LTE��(bi��o)��(zh��n)��TrCH̎��������傀(g��)���E��������������҂���1/3�ľ��a�ʌ�(sh��)�F(xi��n)turbo���a�㷨���Ȼ����Turbo�g�a���м������ڽKֹ�C(j��)�ơ��@ʹ��Turbo��a����Ӌ(j��)���(f��)�s�ȿɔU(ku��)չ����Ȼ�������҂���B����ƥ��������������ͨ�^��(du��)1/3���ʜu݆���a��ݔ���M(j��n)�в������ṩ����o�����ʵľ��a�������B���c�ӉK�ָ�ʹa���ؘ�(g��u)���P(gu��n)�Ĺ��������������������нM������һ�𣬌�(sh��)�F(xi��n)TrCH̎����̎�������������@������������҂�ʡ�����cHARQ̎�����P(gu��n)��MATLAB����(sh��)�Ľ�B����HARQ̎���dz���Ҫ���������?y��n)������|(zh��)�Ϝp�������Δ�(sh��)������������˂�ݔ�K�e(cu��)�`�z�y(c��)֮���������������@��(g��)ʡ�Է����҂����ķ����������ԓ�����P(gu��n)ע�ڷ�(w��n)�B(t��i)�Ñ�ƽ��̎�������
4.4 Turbo ���a
Turbo���a�����ڷQ�鲢�м�(j��)(li��n)���e���a��һ��ŵ����a�㷨[2]����������˼�x���turbo�a��ͨ�^�����B�Ӄɂ�(g��)���y(t��ng)���a����ͨ�^���������������_���γɵ����LTE��Turbo�a���x���ܵ���N���ص�Ӱ푡�������Turbo���a���Ľ����r(n��ng)�s�������������turbo�g�a���������o�����ĵ����Δ�(sh��)�����turbo�a���Ծ����h(yu��n)�h(yu��n)���^���y(t��ng)���e���a�����`�a������������������������ڲ����˄�(chu��ng)�µ�����ƥ��C(j��)�������Turbo���a���m�����Ժ�����ӑՓ���
4.4.1 Turbo���a��
LTE���û������ʞ�1/3��turbo���a�������ŵ����a�����Ļ�ʯ�������D4.3��ʾ��
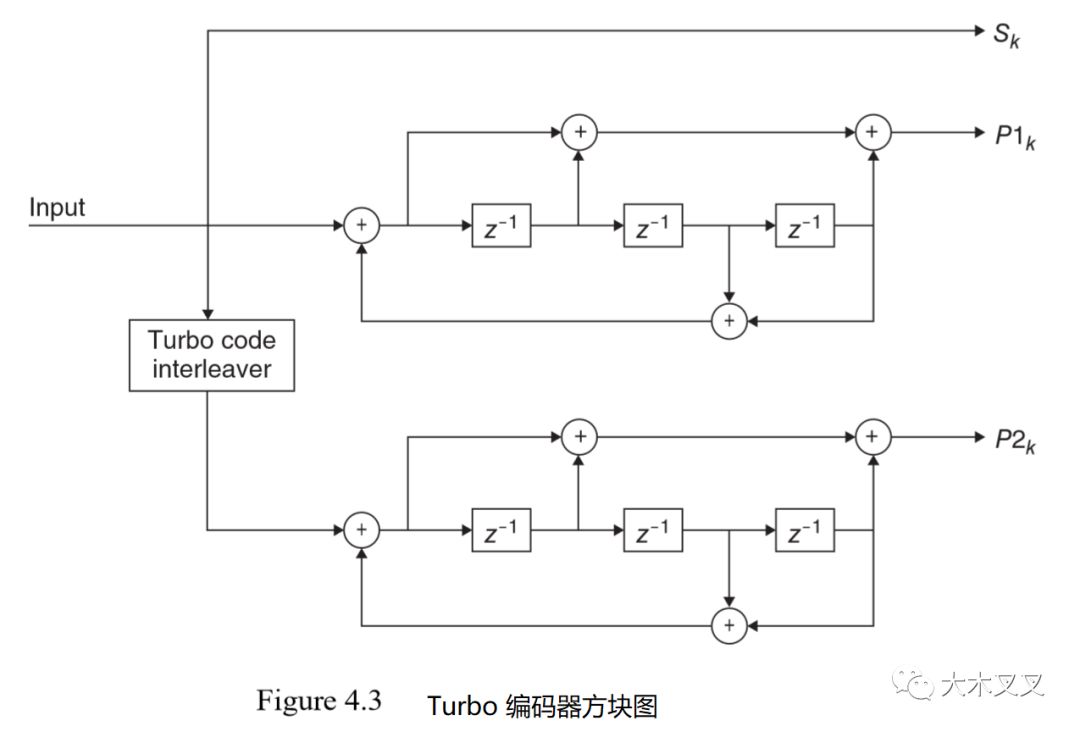
LTE�u݆���a�������Ƀ�(n��i)�����������x�ăɂ�(g��)8��B(t��i)�������a���IJ��м�(j��)(li��n)�����Turbo���a����ݔ��������(g��)�a���M�ɡ���һ����λͨ�����Q��ϵ�y(t��ng)λ����ڶ��͵������ı��ء������ɂ�(g��)�M�ɾ��a����ݔ������ͨ���քe�Q����żУ�(y��n)1����żУ�(y��n)2��������ÿ��(g��)�M�ɾ��a����(d��)������β�����ؽKֹ�������@��ζ����(du��)��Kλ��ݔ��K��С�����ھW(w��ng)��Kֹ�����u݆���a����ݔ��������(g��)�L�Ȟ�K+4λ�����M������@ʹ��Turbo���a���ľ��a����С��1/3��������ÿ��(g��)����ĩβ��·��(f��)��β�������������ϵ�y(t��ng)λ����żУ�(y��n)1����żУ�(y��n)2�����������д�СK+4����
������ȫָ��turbo���a��������҂���Ҫָ���M�ɾ��a����turbo���a��(n��i)���������ľW(w��ng)��Y(ji��)��(g��u)������LTE�������ǻ���һ��(g��)���εĶ��ζ��(xi��ng)ʽ�ÓQ��QPP�������������������ÓQݔ����ص�������ݔ������p(i)��ݔ������i֮�g���P(gu��n)ϵ�����¶��ζ��(xi��ng)ʽ���_(d��)ʽ������
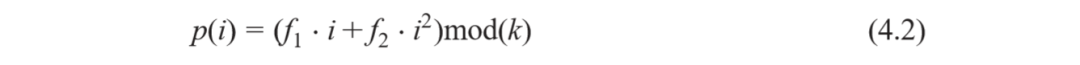
����K��ݔ��K�Ĵ�С������f1��f2��ȡ�Q��Kֵ�ij���(sh��)��LTE���Sݔ��K��СK��188��(g��)��ͬ��ֵ�������С�K��С��40����������K��С��6144�����@Щ�K��С������(y��ng)��f1��f2����(sh��)���īI(xi��n)[3]���M(j��n)���˿��Y(ji��)����
LTE turbo���a����ʹ��QPP�������ğo��(j��ng)�����a�������ͨ�^�ڽ��������Ќ�(du��)�惦(ch��)���L���M(j��n)�����������@������turbo�a�����ܡ��M�ɾ��a���ľW(w��ng)��Y(ji��)��(g��u)�����ɂ�(g��)���(xi��ng)ʽ������

�@������һ��(g��)1/3 Turbo���a�����������Ă�(g��)��B(t��i)�����������ÿ��(g��)�M�ɾ��a��̎���оW(w��ng)��Y(ji��)��(g��u)����ǰ���ͷ����B�Ӷ��(xi��ng)ʽ��ʾ�����˶�ֵ�քe��13��15����
4.4.2 Turbo ��a��
�ڽ��ՙC(j��)������turbo��a����turbo���a����(zh��)�еIJ������������turbo�g�a�����ڃɂ�(g��)У�(y��n)λ��APP���g�a���ͷ����h(hu��n)·�еăɂ�(g��)��������ʹ�����������APP��a����ʹ����turbo���a���аl(f��)�F(xi��n)����ͬ�ľW(w��ng)��Y(ji��)��(g��u)������Լ���ͬ�Ľ���������֮ͬ̎����turbo��a��һ�N�����������turbo�g�a�������ܺ�Ӌ(j��)���(f��)�s��ֱ���P(gu��n)ϵ������(zh��)�еĵ����Δ�(sh��)��
�ڽ��ՙC(j��)̎��turbo��a����(zh��)��turbo���a���������������ͨ�^̎����ݔ����̖(h��o)�������{(di��o)�ͽ�_����ݔ���������turbo��a�����֏�(f��)TrCH��ݔ���ص���ѹ�Ӌ(j��)����Ո(q��ng)ע������Turbo��a��ݔ����Ҫ��LLRs�б�ʾ�����ǰ�����������(zh��)��ܛ�ЛQ���{(di��o)�������t���{(di��o)������LLR��
4.4.3 MATLAB ����
����ăɂ�(g��)MATLAB����(sh��)�@ʾ��LTE��Turobo�a���ͽ�a���Č�(sh��)�F(xi��n)��������Ҏ(gu��)���������ʹ��ͨ��ϵ�y(t��ng)�������ϵ�y(t��ng)��(du��)���������TurboEncoder����(sh��)�������҂�ʹ��comm.TurboEncoderϵ�y(t��ng)��(du��)��������O(sh��)�þW(w��ng)��Y(ji��)��(g��u)�ͽ�������������Ԍ�(sh��)�F(xi��n)LTE��(bi��o)��(zh��n)��ָ���Ĺ�������ͨ�^�{(di��o)��ϵ�y(t��ng)��(du��)���step�������������(du��)ݔ������M(j��n)��̎����������Turbo���a��������ݔ���������
1function y=TurboEncoder(u, intrlvrIndices)
2%#codegen
3persistent Turbo
4if isempty(Turbo)
5 Turbo = comm.TurboEncoder('TrellisStructure', poly2trellis(4, [13 15], 13), ...
6 'InterleaverIndicesSource','Input port');
7end
8y=step(Turbo, u, intrlvrIndices);
9end
��Ƶ�������TurboDecoder����(sh��)��(du��)���һݔ����̖(h��o)(u)�M(j��n)�в���������ԓ��̖(h��o)�ǽ��{(di��o)���ͽ�_����LLRݔ����Turbo��a�����֏�(f��)�l(f��)�ͱ��ص���ѹ�Ӌ(j��)������ԓ����(sh��)߀������������intrlvrIndices���ͽ�a����ʹ�õ��������Δ�(sh��)��maxIter������ݔ�롣
1function y=TurboDecoder(u, intrlvrIndices, maxIter)
2%#codegen
3persistent Turbo
4if isempty(Turbo)
5 Turbo = comm.TurboDecoder('TrellisStructure', poly2trellis(4, [13 15], 13),...
6 'InterleaverIndicesSource','Input port', ...
7 'NumIterations', maxIter);
8end
9y=step(Turbo, u, intrlvrIndices);
10end
�����O(sh��)�þW(w��ng)��Y(ji��)��(g��u)�������҂�ʹ��ͨ��ϵ�y(t��ng)������� ploy2trellis() ����(sh��)�������LTE�W(w��ng)��Y(ji��)��(g��u)ͬ�r(sh��)����ǰ���ͷ����B�Ӷ��(xi��ng)ʽ���҂����Ƚ������(xi��ng)ʽ�Ķ��M(j��n)�Ɣ�(sh��)��ʾ������Ȼ���M(j��n)�Ʊ�ʾ�D(zhu��n)�Q�ɰ��M(j��n)�Ʊ�ʾ��ͨ�^�鿴�D4.3�еĜu݆���a���Ŀ�D����҂����Կ���ԓ���a�����мs���L�Ȟ�4�����������(xi��ng)ʽ��ꇞ�[1315]�ͷ����B�Ӷ��(xi��ng)ʽ��13��������ˣ������O(sh��)�þW(w��ng)��Y(ji��)��(g��u)�������҂���Ҫʹ��poly2trellis(4�����[1315]��13)����(sh��)�����
���˘�(g��u)������QPP������LTE������������҂�ʹ��lteIntrlvrIndices() ����(sh��)��ԓ����(sh��)���ڃH���S��188��(g��)ݔ���С����LTE������������ҵ�����(y��ng)��f1��f2����(sh��)��������(bi��o)��(zh��n)�е�����Ӌ(j��)���ÓQ�����������
1function indices = lteIntrlvrIndices(blkLen)
2%#codegen
3
4[f1, f2] = getf1f2(blkLen);
5Idx = (0:blkLen-1).';
6indices = mod(f1*Idx + f2*Idx.^2, blkLen) + 1;
8end
9
����comm.TurboEncoder��comm.TurboDecoderϵ�y(t��ng)��(du��)���ǻ���ֱ��MATLAB��(sh��)�F(xi��n)�����_(d��)�㷨�Č�(du��)�������������������ʹ��MATLAB�����������҂����ԙz��ÿ��ʹ���@Щϵ�y(t��ng)��(du��)��r(sh��)��(zh��)�е�MATLAB���a����������MATLAB��ϵ�y(t��ng)��(du��)��Ą�(chu��ng)���̈́�(chu��ng)�������˱����ķ�����������P(gu��n)�����}�ĸ�����Ϣ���Ո(q��ng)����MATLAB�ęn[4]���������f��MATLAB��(sh��)�F(xi��n)��η����҂��������������҂����ԙz���@��(g��)ϵ�y(t��ng)��(du��)���stepimpl����(sh��)��
comm.TurboEncoder stepimpl����(sh��)��(zh��)�Ѓɂ�(g��)���e���a�������������ᘌ�(du��)ݔ����̖(h��o)�����Ȼ��ᘌ�(du��)��̖(h��o)�Ľ����汾��Ȼ�������@�c�W(w��ng)��Kֹ���P(gu��n)���~��ӱ������������ӵ�Systematic��Parity����ĩβ�������comm.TurboDecoder stepimpl�؏�(f��)һϵ�в�����������ɂ�(g��)APP��a���ͽ�������N��������Nֵ��(du��)��(y��ng)��turbo��a���е��������Δ�(sh��)���������ÿ��(g��)̎�������Y(ji��)���r(sh��)���turbo��a��ʹ�ýY(ji��)����������ѹ�Ӌ(j��)������
4.4.4 �`�a�ʜy(c��)��
�κ�turbo���a��������ȡ�Q���ڽ�a�����Ј�(zh��)�еĵ����Δ�(sh��)���@��ζ�����������(du��)�ڽo���Ĝu݆���a�����������LTE��(bi��o)��(zh��n)��ָ���ľ��a�������S�������Δ�(sh��)����������BER������u׃����������(sh��)chap4_ex03_nIterͨ�^Ӌ(j��)����������Δ�(sh��)�ĺ���(sh��)��BER���܁��f���@һ�c(di��n)������
1function [ber, numBits]=chap4_ex03_nIter(EbNo, maxNumErrs, maxNumBits, nIter)
2%% Constants
3clear functions;
4FRM=2432; % Size of bit frame
5Indices = lteIntrlvrIndices(FRM);
6M=4;k=log2(M);
7R= FRM/(3* FRM + 4*3);
8snr = EbNo + 10*log10(k) + 10*log10(R);
9noiseVar = 10.^(-snr/10);
10ModulationMode=1; % QPSK
11%% Processsing loop modeling transmitter, channel model and receiver
12numErrs = 0; numBits = 0; nS=0;
13while ((numErrs < maxNumErrs) && (numBits < maxNumBits))
14 % Transmitter
15 u = randi([0 1], FRM,1); % Randomly generated input bits
16 t0 = TurboEncoder(u, Indices); % Turbo Encoder
17 t1 = Scrambler(t0, nS); % Scrambler
18 t2 = Modulator(t1, ModulationMode); % Modulator
19 % Channel
20 c0 = AWGNChannel(t2, snr); % AWGN channel
21 % Receiver
22 r0 = DemodulatorSoft(c0, ModulationMode, noiseVar); % Demodulator
23 r1 = DescramblerSoft(r0, nS); % Descrambler
24 y = TurboDecoder(-r1, Indices, nIter); % Turbo Deocder
25 % Measurements
26 numErrs = numErrs + sum(y~=u); % Update number of bit errors
27 numBits = numBits + FRM; % Update number of bits processed
28 % Manage slot number with each subframe processed
29 nS = nS + 2; nS = mod(nS, 20);
30end
31%% Clean up & collect results
32ber = numErrs/numBits; % Compute Bit Error Rate (BER)
33
���˱��^turbo���a���͂��y(t��ng)���e���a����������������҂�߀�\(y��n)����һ��(g��)����chap4_ex03_viterbi.m�ĺ���(sh��)����ʹ����1/3���ʵľ��e���a������Viterbi��a����ܛ�ЛQ���{(di��o)�����
1function [ber, numBits]=chap4_ex03_viterbi(EbNo, maxNumErrs, maxNumBits)
2%% Constants
3FRM=2432; % Size of bit frame
4M=4;k=log2(M);
5R= FRM/(3* (FRM+6));
6snr = EbNo + 10*log10(k) + 10*log10(R);
7noiseVar = 10.^(-snr/10);
8ModulationMode=1; % QPSK
9%% Processsing loop modeling transmitter, channel model and receiver
10numErrs = 0; numBits = 0; nS=0;
11while ((numErrs < maxNumErrs) && (numBits < maxNumBits))
12 % Transmitter
13 u = randi([0 1], FRM,1); % Randomly generated input bits
14 t0 = ConvolutionalEncoder(u); % Convolutional Encoder
15 t1 = Scrambler(t0, nS); % Scrambler
16 t2 = Modulator(t1, ModulationMode); % Modulator
17 % Channel
18 c0 = AWGNChannel(t2, snr); % AWGN channel
19 % Receiver
20 r0 = DemodulatorSoft(c0, ModulationMode, noiseVar); % Demodulator
21 r1 = DescramblerSoft(r0, nS); % Descrambler
22 r2 = ViterbiDecoder(r1); % Viterbi Deocder
23 y=r2(1:FRM);
24 % Measurements
25 numErrs = numErrs + sum(y~=u); % Update number of bit errors
26 numBits = numBits + FRM; % Update number of bits processed
27 % Manage slot number with each subframe processed
28 nS = nS + 2; nS = mod(nS, 20);
29end
30%% Clean up & collect results
31ber = numErrs/numBits; % Compute Bit Error Rate (BER)
32end
33
�D4.4���^�ˮ�(d��ng)ʹ��Turbo��a��һ���������λ���ε����cͬ�Ӿ��a���ʵĵ��;S�رȽ�a���r(sh��)Turbo��a����BER���������S�������Δ�(sh��)��1�����ӵ�3�������Ȼ�����ӵ�5�Σ��҂�����BER�������Πӳ��Turbo�g�a���Ľ�����|(zh��)������ԓ������E/Nһ��ֵ��ʬF(xi��n)���͵�б��������������������5�ε������������Δ�(sh��)�����Y(ji��)��QPSK��ܛ�ЛQ���{(di��o)����LTE turbo��a���܉��_(d��)��1.25dB�������ֵ2e_4�����
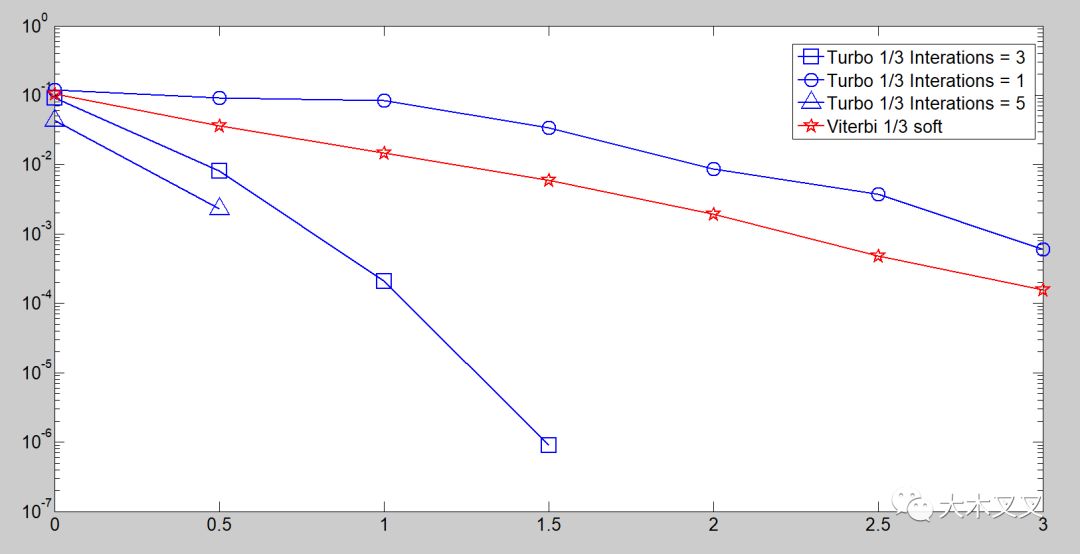
�D4.4 ��ͬ�����Δ�(sh��)��r�µ�Turbo���a�c���e���a�`�a�ʌ�(du��)�ȈD
turbo���a���@�N�����������Խ�ጞ�ʲô��LTE��(bi��o)��(zh��n)��turbo���a���x�������Ñ���(sh��)��(j��)�ď�(qi��ng)���ŵ����a�C(j��)�����
ͨ�^��(zh��)�������_����chap4_ex03_nIter����������҂����Ԝy(c��)����������Δ�(sh��)�ĺ���(sh��)���հl(f��)��Ӌ(j��)��r(sh��)�g���Ӌ(j��)��r(sh��)�g�nj�(du��)turbo���a�ͽ�a������Ӌ(j��)���(f��)�s�ȵĹ�Ӌ(j��)��
1%% Computation time of turbo coder
2%% as a function of number of iterations
3EbNo=1;
4maxNumErrs=1e6;
5maxNumBits=1e6;
6for nIter=1:6
7 clear functions
8 tic;
9 ber=chap4_ex03_nIter(EbNo, maxNumErrs, maxNumBits , nIter);
10 toc;
11end
12
��4.4���Y(ji��)�˽Y(ji��)�����������A(y��)�ڵģ���(f��)�s���Լ������ɽ�a��������ĕr(sh��)�g�c�����Δ�(sh��)������������
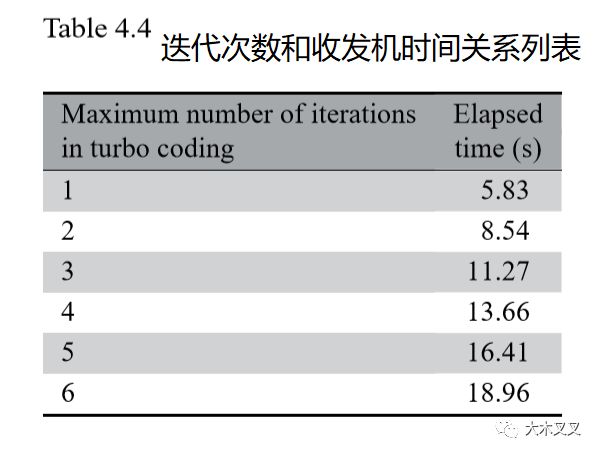
�����˽�ʲô����(sh��)��(du��)�҂������ֹ�_�l(f��)���հl(f��)����chap4_ex03_nIter���ď�(f��)�s��ؕ�I(xi��n)����҂���(zh��)�����·����_������
1%% Profiling the turbo coder system model
2EbNo=1;
3maxNumErrs=1e6;
4maxNumBits=1e6;
5profile on
6ber=chap4_ex03_nIter(EbNo, maxNumErrs, maxNumBits , 1);
7profile viewer
ϵ�y(t��ng)ģ�͵�ÿ�еĈ�(zh��)�Еr(sh��)�g���Y(ji��)�ڈD4.5��ʾ�ķ�����(b��o)�������
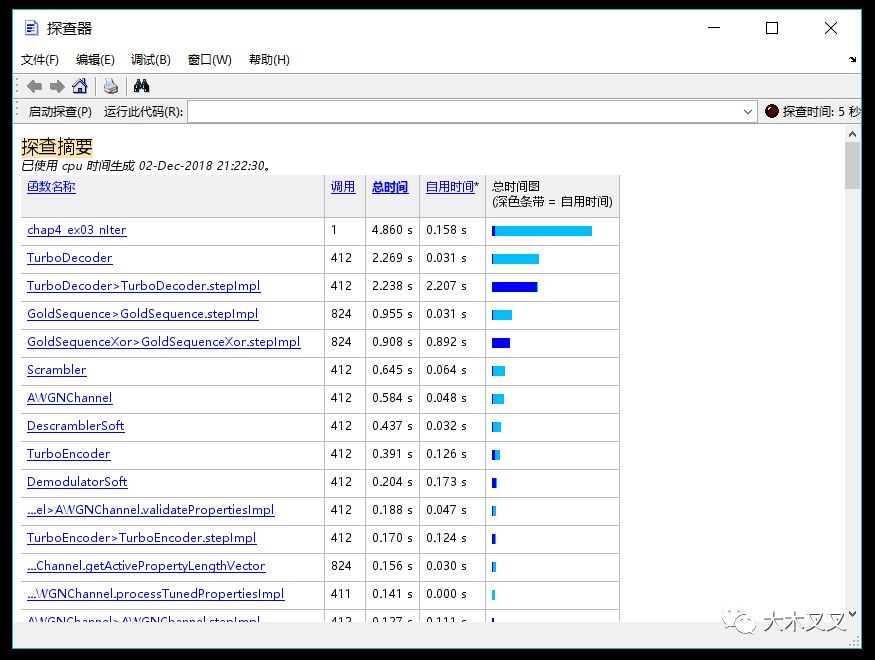
�Y(ji��)�����������ù̶��ĵ���ֵ�M(j��n)��Turbo�g�a�sռ����(g��)ϵ�y(t��ng)����r(sh��)�g��86%������������Turbo�g�a�����J(r��n)����ϵ�y(t��ng)��ƿ�i֮һ����������˿˷��@��(g��)���}�����LTE��(bi��o)��(zh��n)��LTE���a�����ṩ��һ�N�C(j��)�ƣ�ԓ�C(j��)��ʹ���܉�M��KֹTurbo�g�a����������(hu��)��(du��)Turbo�g�a�����ܮa(ch��n)����(y��n)��Ӱ��������@�N���ڽKֹ�C(j��)�ƌ�����һ��(ji��)��ӑՓ��
���m(x��)
2018/12/2
�c(di��n)���P(gu��n)ע�˽���ྫ�ʃ�(n��i)�ݣ���������






